

Understanding UTF-8 in PDF 2.0
Excerpt: PDF Association’s CTO, Peter Wyatt discusses text strings in PDF.
About the author: Peter Wyatt is the PDF Association’s CTO and an independent technology consultant with deep file format and parsing expertise, who is a developer and researcher actively working on PDF technologies … Read more

Contents
In PDF “text strings” are a formal subtype of strings as illustrated in Figure 7 from ISO 32000-2:

Text strings in PDF are intended for character strings that could be presented to a human, such as in a graphical user interface or in the output from command-line utilities. Because modern PDF text strings support Unicode they can reliably represent any character, symbol or pictograph from any language or symbol set supported by Unicode.
Unicode describes itself as “… a character coding system designed to support the worldwide interchange, processing, and display of the written texts of the diverse languages and technical disciplines of the modern world. In addition, it supports classical and historical texts of many written languages.”
A Brief History
PDF 1.0 originally defined only PDFDocEncoding as the default text encoding used throughout PDF for “outline entries, text annotations, and strings in the Info dictionary” (Adobe PDF 1.0, p.185). With the introduction of PDF 1.2 in November 1996, Adobe added support for Unicode using the UTF-16BE encoding, although the PDF 1.2 reference does not refer to the specific encoding as “UTF” (the UTF-16 terminology was only introduced a few months before PDF 1.2 shipped).
PDFDocEncoding is a predefined text encoding unique to PDF. It supports a superset of the ISO Latin 1 character set which happens, as Adobe’s PDF Reference 1.2 puts it, to be “compatible with Unicode in that all Unicode codes less than 256 match PDFDocEncoding” (Adobe PDF 1.2, p.47).
In 2017, PDF 2.0 introduced UTF-8 encoded strings as an additional format for PDF text strings, while maintaining full backward-compatible support for the existing UTF-16BE and PDFDocEncoded text string definitions. Since PDF 1.7 was originally published back in 2006, UTF-8 had become the lingua franca of the web, operating systems, and many programming languages. Accordingly, adding UTF-8 support to PDF 2.0 aligned the ubiquitous file format with this trend, and reduced the burden on conversion technologies to translate between Unicode encodings.
By requiring the use of Unicode Byte Order Markers (BOMs) at the start of all Unicode PDF text strings, a PDF implementation can easily and unambiguously identify the encoding of each data point. The 3-byte BOM for PDF UTF-8 text strings is 239, 187 and 191 in decimal (357, 273, 277 in octal and EF, BB, BF hexadecimal). Note also that there is no requirement in PDF that all text strings in a file must use the same encoding so a single PDF file may contain text strings in all three encodings. As described in the PDF specification and elsewhere, the selected byte values of the BOMs are “… unlikely to be a meaningful beginning of a word or phrase”.
Furthermore, both kinds of PDF Unicode text strings (UTF-8 and UTF-16BE) also support internal language escape sequences using a 2-byte BCP 47 language tag with an optional 2-byte ISO 3166 country code allowing the languages of Unicode text strings to be unambiguously specified. For example, the single literal PDF text string (�33enUSHello �33esMXHola) identifies “Hello” as US English and “Hola” as Mexican Spanish with �33 being the octal value of ESCAPE (27 decimal).
Use of PDF text strings
Referring back to ISO 32000-2 Figure 7 above, it can be seen that not all strings in PDF are “text strings”. PDF carefully defines the use of a “text string” for those data points that can contain strings that are intended for human consumption. By using the Arlington PDF Model to grep for “string-text”, or by using the text search capability in your favorite PDF viewer for the term “text string”, this term occurs in over 90 individual data points including:
- PDF page labels
- PDF outlines (aka “Bookmarks”)
- PDF Document Information such as Author, Subject, Title, Keywords, etc.
- Many annotation features, including interactive form fields
- Features related to collections and embedded files
- Measurement viewports and number formats
- Optional Content layer names, configuration names, user names, etc.
- Tagged PDF support for Alt text, ActualText, Expansion text (E), etc.
Using the latest Arlington PDF Model, the following Linux shell commands can be used to identify and count all unique PDF text strings:
$ cd ./tsv/latest $ grep -h "string-text" * | cut -f 1-2 | sort | uniq | wc -l $ grep "string-text" *
Many of these features pertain to user interface elements in interactive PDF viewers, although not all viewers may support all features. Command-line and server-based PDF processors may also generate output that includes content from many of these features.
A very common misunderstanding about PDF relates to textual page content – such content is not natively stored as Unicode in PDF. This is because PDF is a fully type-set paginated page description language based on precise glyph appearances. The PDF page is the output after various kerning, text shaping, complex text layout, and reflow algorithms have all done their job. This quality is what gives PDF its inherently reliable appearance model. Reliable Unicode text extraction of page content may require PDF creation software to ensure that any additional information about the character, or characters, that each glyph represents is also added to the PDF. This is fully described in clause 9 of ISO 32000.
Testing PDF UTF-8 support
It is now over 4 years since PDF 2.0 with UTF-8 support was first officially published as ISO 32000-2:2017. Most PDF viewers should therefore be expected to correctly handle UTF-8 text strings.
As a variable-width encoding, UTF-8 is also backwards compatible with ASCII. This means that UTF-8 strings that use only the standard Latin alphabet with 1 byte per character – in the same way as PDFDocEncoding – will only have the 3 byte BOM as the distinguishing characteristic. This tends to make evaluation of PDF technologies difficult as more complex UTF-8 sequences are necessary.
To help both end-users and developers assess PDF technologies, I have created a PDF 2.0 test file that uses UTF-8 and UTF16-BE text strings across many PDF features including bookmarks (outlines), optional content layer names, page labels, and document information. The test file “pdf20-utf8-test.pdf” is in the PDF Association’s GitHub repository for PDF 2.0 examples (https://github.com/pdf-association/pdf20examples) and is best used in an interactive viewer. Note that it is not a comprehensive test of every possible PDF text string, nor is it a complete test of UTF-8 support.
User interfaces and console applications that do not correctly support PDF 2.0 UTF-8 text strings will most likely interpret the 3-byte UTF-8 BOM as bytes in PDFDocEncoding, thus displaying or outputting at least 3 leading “junk” characters. The decimal byte values 239, 187 and 191 in PDFDocEncoding represent i dieresis (ï), right-pointing double angle quotation mark (»), and inverted question mark (¿) respectively.
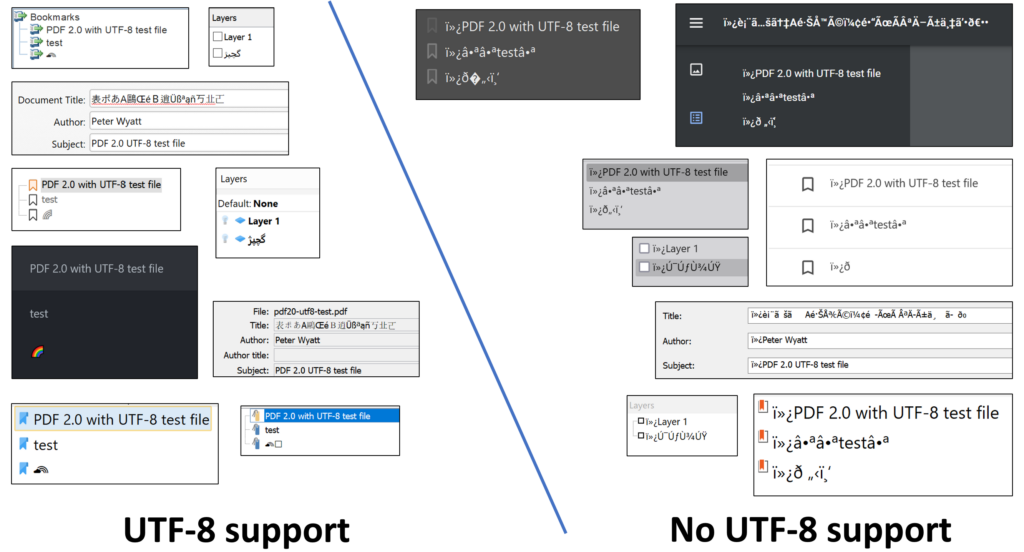
Output from various interactive PDF viewers shows differing levels of PDF 2.0 UTF-8
support for outlines, layers and document information.
Selected UTF-8 text strings in the PDF 2.0 test file are from the Big List of Naughty Strings (BLNS, https://github.com/minimaxir/big-list-of-naughty-strings) so some of the UTF-8 strings in this PDF 2.0 test file use PDF hexadecimal strings which make it awkward to see what should be displayed in a user interface. A Linux console correctly configured to support UTF-8 using the locales package can be used to convert UTF-8 PDF hex strings copied from the PDF into visible glyphs:
$ export LC_ALL=en_US.UTF-8 $ export LANG=en_US.UTF-8 $ export LANGUAGE=en_US.UTF-8 # confirm UTF-8 support is now configured using “locale” command $ locale LANG=en_US.UTF-8 LANGUAGE=en_US.UTF-8 LC_CTYPE="en_US.UTF-8" LC_NUMERIC="en_US.UTF-8" LC_TIME="en_US.UTF-8" … # Including 3-byte UTF-8 BOM as copied directly out of the PDF (EF BB BF) $ echo EF BB BF DA AF DA 86 D9 BE DA 98 | xxd -r -p گچپژ # Without 3-byte UTF-8 BOM (which is not required by Linux) $ echo DA AF DA 86 D9 BE DA 98 | xxd -r -p گچپژ $ echo E8 A1 A8 E3 83 9D 41 E9 B7 97 C5 92 C3 A9 EF BC A2 E9 80 8D C3 9C C3 9F C2 AA C4 85 C3 B1 E4 B8 82 E3 90 80 F0 A0 80 80 | xxd -r -p 表ポA鷗ŒéB逍Üߪąñ丂㐀 $ echo F0 9F 8C 88 EF B8 8F 0A | xxd -r -p ️
Conclusion
Unlike when PDF 1.7 was released, today, UTF-8 dominates the web and has become the de facto character encoding for operating systems and programming languages. PDF 2.0 first added support for UTF-8 back in 2017. As the adoption of PDF 2.0 increases, it is important for all users to know that their PDF technology platforms and investments correctly support the presentation of navigation and interactive elements that can be encoded as UTF-8.