

SafeDocs unearths PDF inline image issue
Excerpt: This freely-available PDF file includes 8 test cases that only render correctly if the abbreviated key name is used. If the full key name is used then something else happens (precisely what is implementation dependent!).
About the author: Peter Wyatt is the PDF Association’s CTO and an independent technology consultant with deep file format and parsing expertise, who is a developer and researcher actively working on PDF technologies … Read more

Researchers in the DARPA-funded SafeDocs project are pushing the state-of-the-art in Data Definition Languages (DDLs) by attempting to formally capture and encode all the rules of the PDF file format. These formalisms can identify ambiguities, unstated requirements and other issues.
A recent discovery unearthed using these formal approaches had remained undiscovered since PDF 1.0 back in 1993! The issue is that inline images can use either full key names from Image XObjects or for many keys an equivalent short abbreviated key, as listed in Table 91 of ISO 32000-2:2020. The ambiguity occurs when both a full key and an abbreviated key for the same semantic entry are present in a single inline image.
This issue was one of the first logged into the PDF Association’s pdf-issues GitHub repository as Issue #3. Timing was such that it just missed the publication of ISO 32000-2:2020 in December 2020, so the PDF Association’s PDF Technical Working Group reviewed the issue and established the following industry-agreed resolution:
In the situation where both an abbreviated key name and the corresponding full key name from Table 91 are present, the abbreviated key name shall take precedence.
This resolution will pass to ISO TC 171 SC 2 WG 8 (the working group responsible for ISO 32000) for inclusion in a future edition, however the ISO WG can alter the industry resolution.
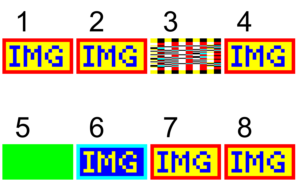
I have created a single page hand-crafted targeted PDF test file that tests 8 semantic key collisions in inline image dictionaries. This freely-available PDF file is specifically designed so that each of the 8 test cases will only render correctly (as the blue blocky “IMG” text on a yellow background with a red border) if the abbreviated key name is used. If the full key name is used then something else entirely will happen (precisely what will happen is implementation dependent!).

A correct implementation will render 8 iterations of the above image.
I have included comments in the PDF test file and created it such that it may safely be viewed in a text editor. It includes the following structure in the page content stream for each of the 8 semantic key collisions:
- Black text is used to paint the test number (1-8). If the text does not appear then the PDF processor has likely either entirely aborted the page content stream or has failed in attempting to recover from incorrectly processing a full key name earlier in the content stream; however it might “resync” with the content stream operators further down the content stream.
- A solid green rectangle is painted directly beneath the inline image using the re operator. If this green rectangle is visible then the PDF processor has failed to paint the inline image which immediately follows it in the content stream.
- A 20 x 10 pixel inline image with a single semantic key collision is then painted. This is the actual semantic test to determine whether the full key name or abbreviated key name is used by the renderer. The pixel data always uses one of the standard PDF ASCII-based filters to ensure that the PDF file is text-editor friendly.
In their blog post “Room for Disagreement”, the Galois researchers and I describe some of the tools and techniques used in SafeDocs that helped uncover this specific issue, as well as other issues in the PDF specification. They also detail each of the 8 semantic test-cases in greater detail.
| Test Number | Description |
|---|---|
| 1 | Only full keys are used – all PDF processors should render this correctly. |
| 2 | Only abbreviated keys are used – all PDF processors should render this correctly. |
| 3 | The Width/W and Height/H entries for the inline image dimensions are duplicated. |
| 4 | The Filter/F entry is duplicated with different values. |
| 5 | The ColorSpace/CS entry is duplicated with different values. |
| 6 | The Decode/D entry is duplicated with different values. |
| 7 | The Interpolate/I (capital i) entry is duplicated with different values. The final rendered appearance of this inline image may thus appear smoothed or blurred for those implementations that support interpolation. |
| 8 | The DecodeParms/DP entry is duplicated with different values for a Flate filter. Two filters are also used (ASCIIHexDecode and FlateDecode). |
A quick test of popular PDF viewing implementations across multiple vendors and platforms using this test PDF file shows that no vendor has yet fully and correctly implemented the recommended resolution and that almost all implementations have unique behaviour! This is somewhat unexpected, since intuition might imply that some implementers may have privately identified this issue and chosen their own consistent solution. However the random results using this test file indicates that parsing and processing of semantic collisions in inline image dictionaries is inconsistent.
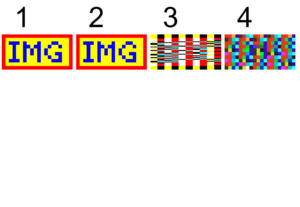
As this issue is newly discovered and only recently resolved in the respective industry forum, PDF viewers and renderers cannot be expected to have already implemented and released their solutions. Now, with the test file freely available, and clearly documented, I expect to see resolutions in the marketplace very soon, which should also help persuade the ISO WG to adopt the industry resolution.