
Large Scale Testing and Analysis of PDF to PDF/A Conversion
Excerpt: We’ve been running our PDF/A conversion tools across some large corpora, created by the Open Preservation Foundation, consisting of 15,083 PDF documents. Here’s what we’ve learned in the process.
About the author:

Contents
A major aspect of the recent 2.26 release of our PDF Library has been PDF to PDF/A conversion, which we’ve talked about in detail already.
In this article I wanted to discuss the results of our large scale testing of this functionality. As touched on previously, we’ve been running our converter over a large batch of documents known informally as GovDocs Selected. This is a subset of the Govdocs1 corpora, a selection of one million documents scraped from US government websites back in 2010.
This is a well known collection of documents but its sheer scale is a little daunting for proper analysis, so we’ve been using the “selected” subset created by the Open Preservation Foundation, which consists of 15,083 PDF documents. Unfortunately the direct link to this subset is no longer available, but hopefully this is something that will be fixed in the near future – we’ll update this article with a link when it is.
Testing Process
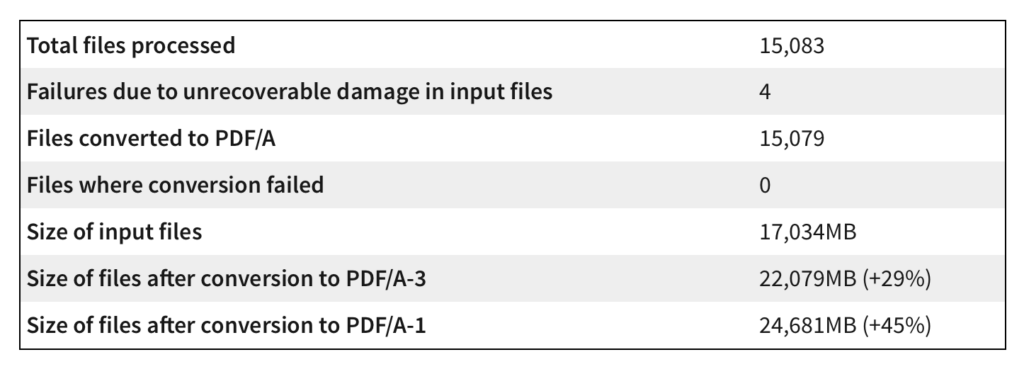
Our testing procedure with these documents involves using our current in-house release, which has a few changes over 2.26.1 of our Java PDF Library – largely optimizations resulting from the first run of this analysis, in fact. We used our API to convert the 15,083 PDF documents from this Corpora to both PDF/A-1 and PDF/A-3, verifying the results in a second pass with our API to ascertain that the conversion succeeded.
The code used for this is almost identical to that published in our previous article.
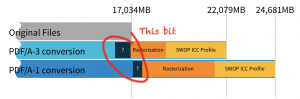
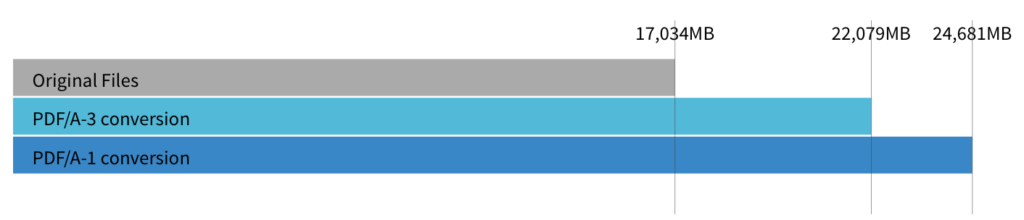
PDF/A-3 allows us to keep attachments but is otherwise very close to PDF/A-2. Exactly 1% of the archive had embedded files – these were almost all “joboptions” files to configure printing, and of negligible size. So the numbers for PDF/A-3 represent what we’d see with PDF/A-2. Here are those numbers, with percentages showing how much the files expanded by.
Analysis
Let’s start with the obvious: conversion to PDF/A is going to make the files bigger, and conversion to PDF/A-1 is worse than PDF/A-3.
The reason for this is that PDF/A-2 and 3 are based on PDF 1.7, while PDF/A-1 is based on PDF 1.4. This has three main consequences:
- PDF 1.4 disallows transparency – if a page has transparency, we have to rasterize it to a bitmap.
- PDF 1.4 disallows “object stream compression” (which we call Compressed XRef in our API). This technique can reduce the file size.
- PDF 1.4 has more architectural restrictions, such as limits on numbers and the length of strings.
We quantified the cost of these. first by running the PDF/A-3 conversion without object stream compression – the size increase was 946MB. Only 1,047 (7%) of our sample files used object compression, although considering that the GovDocs corpora is over 11 years old that may not be representative of a more modern set of files.
For this archive, we estimate that enabling object compression with PDF/A-3 saved us 5.1% of the original archive size, whereas removing it from files that have it already, as we must for PDF/A-1, cost us 0.6%.
Analysis: rasterization of pages
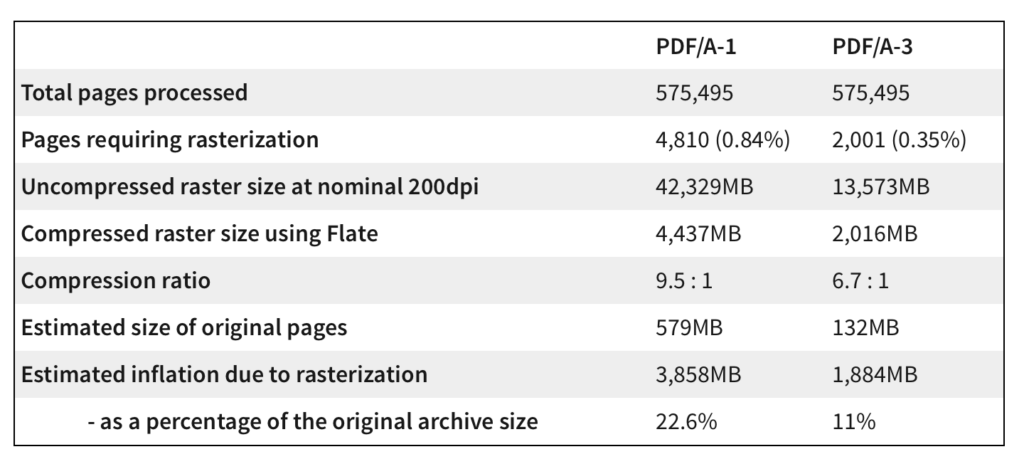
When a page can’t be made valid for PDF/A for any reason, we have to rasterize it to a bitmap – the original page is replaced with the bitmap copy, overlaid with “invisible text” to make the page searchable and the text selectable.
In our test the cause was variable, but included no suitable font being available for substitution, an inability to resolve duplicate color separations, structural issues such as nesting levels being too deep, or (for PDF/A-1) transparency. We were surprised to find a significant cause was pages containing embedded fonts with embedding restrictions: this is disallowed in PDF/A, but as many were symbol or non-unicode fonts we were unable to find a replacement.
We’ve chosen a nominal resolution of 200dpi, although for very large pages this is automatically reduced to prevent out-of-memory conditions: one page in the test corpora is over 600km on each side, which we presume is down to error rather than ambition by its author.
It’s easy to track the size of the rasters we generate for this, so we know exactly how much space the rasterized version of each page takes up. Calculating the space used by the original versions of those pages is much harder, as pages typically share resources. We took an estimate by loading each PDF, deleting the pages we rasterized, saving the PDF and computing the differences in filesize.
Conclusions? First, it’s easy to see how much better PDF/A-3 performs here. The additional pages rasterized under PDF/A-1 will be almost all due to the use of transparency, blend modes etc. – at first glance it appears these compress better on average, which is an interesting result if true.
We use Flate compression to compress the image by default, a lossless algorithm used in PNG and Zip. Even though it reduces pages to roughly 10-15% of their original size, it’s still a lot of data to store. A focus in future revisions of our software will be to reduce this number as much as we can.
Can we improve on the size of each rasterized page? Yes, but at a cost.
There are three parameters we can control when converting a page to a bitmap, and the article we wrote on this topic 13 years ago still applies: reduce the number of pixels, the number of bits, or change the compression algorithm.
We chose 200dpi; anecdotally we find below 150dpi the pixelization becomes visible at typical viewing resolutions. Reducing the number of bits isn’t useful in this case; the causes for rasterization often involve problems with color including (for PDF/A-1) transparency. While many pages may rasterize at 1-bit without significant loss, most of those that can do not require it. Pages that do are typically in full color.
Finally, we could use a different compression algorithm. For PDF color images there are only three real contenders:
- Flate compression – lossless and fast, it’s what we use by default.
- Discrete-cosine (DCT) compression, as used in JPEG. This is lossy, fast, and excellent for photos, but introduces visible noise when used to represent line graphics or text. For this reason alone, we’ve discounted DCT compression as a useful option. Introducing visible artifacts to a PDF intended for long-term archiving doesn’t seem right.The 2004 paper Quantitative analysis of image quality of lossy compression images suggests that to improve on our roughly 8 : 1 compression ratio, we would need to reduce the JPEG quality factor below 0.87; although as that paper was based on photographic test images, it may not be representative of text-heavy pages compressed with DCT. This might be something we’ll investigate in the future.
- JPEG2000 compression, which can be lossless or lossy. The lossy compression is more common, and gives much better results for images containing line graphics or text than DCT. It was introduced in PDF 1.6 so can only be used with PDF/A-2 or later.
We have a JPEG2000 API available to use which supports compression, so we chose a document at random and rasterized its 32 pages. Using Flate compression it took 5s to rasterize and 8.4s to compress to 10.5% of the original size. With JPEG2000, the default settings reduced that size by half but compression time went up to 29.1s. Each page takes 3 times longer to generate.
If you are short on disk space and have time or CPU capacity to spare, JPEG2000 compression is a good option. However in our experience it’s usually the other way around. And as mentioned, JPEG2000 was introduced in PDF 1.6 – so it’s not available for PDF/A-1.
Analysis: embedded ICC Profiles
58.4% of the 15,079 files had device-dependent CMYK color, requiring us to embed a CMYK ICC profile. We’d arbitrarily chosen a version of US Web Coated SWOP from 2000, which is 544kB (375kB compressed with Flate for storage in PDF). We can immediately calculate that this ICC profile alone accounts for exactly 15,079 * 0.584 * 375kB = 3,224MB – that’s 14.6% of the PDF/A-3 archive!
As we now know the space used for ICC profiles, the expansion caused by page rasterization, and we’ve made a guess at the space we saved by requiring (or disallowing) object compression, we can see how these stack up.
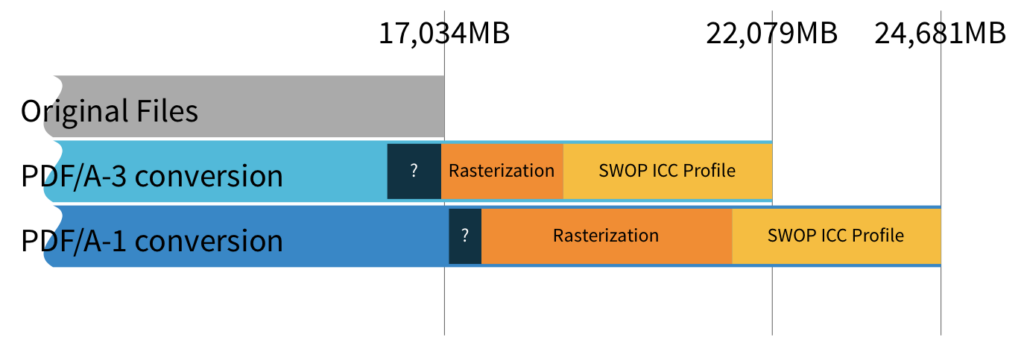
The SWOP ICC profile isn’t necessarily the best choice, in Europe you might prefer FOGRA39. There are a few versions of FOGRA39 available. Let’s see how our chart would stack up with various choices (each chart label is a link to the website containing the ICC profile).
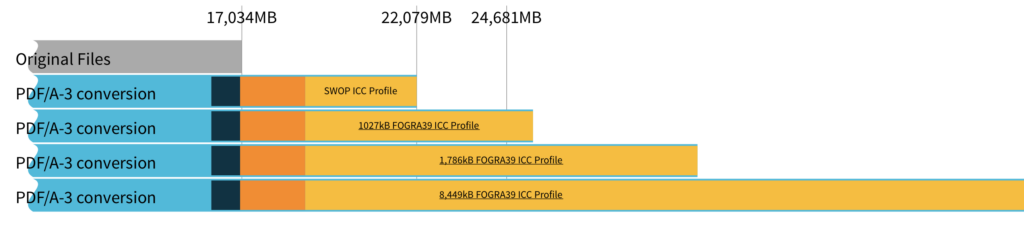
That last profile from color.org is 7.5MB compressed. In our sample, repeated copies of that profile would make up over 80% of our PDF/A-3 archive! You would need a screen over 8000 pixels wide to see the full bar. You might want to steer clear of that one.
It’s very clear that for a large archive, the ICC profile potentially makes an absurdly large proportion of the data. What can we do about it?
First, why FOGRA39 in particular? In Europe at least there are really only three contenders: FOGRA27, FOGRA39 and FOGRA51, corresponding to ISO12647-2:2004, ISO12647-2:2004/Amd 1 and ISO 12647-2:2013 – informally known as “ISO Coated”, “ISO Coated v2” and “PSO Coated v3”. We recommend FOGRA39 partly based on the assessment of experts:
“I attended a Color Experts day at FOGRA last year, it is follow-up from that event which leads me to suggest their characterization and profiles. Yes, FOGRA 51 is the more recent target; it has a somewhat wider gamut and takes into account optical brighteners in the paper (which requires using a spectrometer with no UV-cut filter, for example). So if you are a commercial print house, and want consistent printing across all your sites, 51 is a better target. For a single CSS predefined CMYK space (where people can’t be bothered to create a profile), the more modest and widely supported FOGRA 39 looks like a better choice.”
It’s also the profile you get in Acrobat DC by default for any of the “European” settings. Other profiles are available, but it’s a good choice for a default.
Are there any smaller options? Currently, we haven’t found any, but we’re trying to commission one and hope to have something to report on this fairly soon. The good news is there’s a lot of room for improvement in the existing ICC profiles – even the smallest option available has data that can be dropped. We’re anticipating a final profile of about 100kB as a reasonable target.
Those coming from the PDF world may not be aware of the recent work done by the CSS working group for HTML (BFO is an active member of that working group). The recently approved css-color-4 standard has brought CMYK color to the web for the first time, along with Lab and ICC color. As of today it’s largely implemented by Apple already in their Safari browser, and is being implemented in Chromium. We expect Firefox to follow shortly. There’s interest in a smaller FOGRA39 profile to support this effort, so it’s definitely a problem in need of a solution.
If you’re wondering how this process might work, I’d highly recommend the articles by Clinton Ingram on how he produced the saucecontrol profiles. A bit niche, but consider that your author has a large, carefully curated collection of ICC profiles.
Analysis: what’s left over
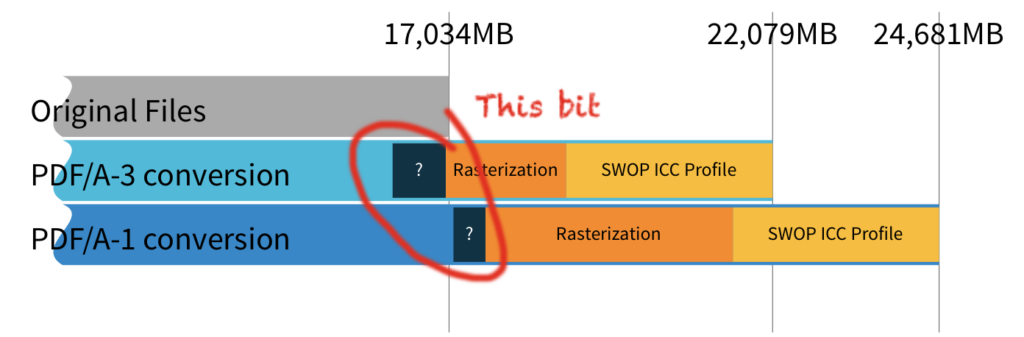
About 830MB (3.8%) of our PDF/A-3 archive and 500MB (2%) of our PDF/A-1 archive is unaccounted for. We haven’t done a full analysis here: some inflation is unavoidable, the causes more varied, and the number of estimates we’re building these figures on is getting larger.
For PDF/A-1, some of the additional weight may be due to conversion of JPEG2000 to Flate, and JBIG2 to CCITT, that are required for the older standard. But most of the inflation is undoubtedly due to fonts, which have to be embedded for PDF/A. Our PDF/A-1 archive has 2,809 additional rasterized pages – that’s 2,809 less pages requiring fonts, which likely accounts for some of the difference.
We haven’t been very scientific with our choice of fonts, simply giving each PDF the choice of Times, Arial and Noto Sans CJK Sc; not a very tailored choice for a bunch of US Government documents. The latter was chosen because it has a wide range of glyphs not in the other fonts, making it useful for “mopping up” glyphs that aren’t in any other fonts, and we didn’t expect it to be used much.
In fact analysis shows it was embedded in 194 of the PDF/A-1 files – at 1.3%, that’s more than expected. It was often chosen as a substitution for non-chinese fonts purely on the basis that its glyph metrics were closest to the original font (in fact, on our first run of these tests it was used in 8% of the files. We adjusted our weighting algorithm to favour smaller fonts as a result).
If there’s a lesson here, it’s that it’s important to provide a representative selection of fonts for the API to choose from, and to be careful when proving a large font to “mop up” any remaining glyphs. If it’s too large you’ll pay for that in filesize.
So choose carefully. It’s easy to get a list of fonts used in a PDF – with our API, it’s retrieved from the OutputProfile calculated as the first step before conversion. Selecting which fonts to choose from based on the list is certainly possible, and a time spent optimizing this for the documents you’re working with is unlikely to be wasted.
Conclusion
These are the results from one Corpora, but other than being slightly more weighted to older documents and almost exclusively restricted to the latin alphabet, it provides a good cross section. There’s quite a bit we can learn from it.
- Use PDF/A-3 or PDF/A-2 instead of PDF/A-1 if possible.
- The default settings for image rasterization (200dpi and Flate compression) are hard to beat.
- Think carefully about the ICC profile you choose to embed.
- Try to choose your fonts based on the documents you’re working with.
- Try to stay current with our API. We’ll be reducing the number of rasterizations, tweaking the font selection algorithm and turning on object compression by default for PDF/A-2 and PDF/A-3 profiles in the next release.
The numbers above are based on our current internal build, which improved over results from 2.26.1, which in turn improved over results from 2.26. Progress is inevitable.
Happy archiving.